I did a video interview for IamPulse, a small and growing company out of Okta that is focused on simplifying and teaching cloud security. I talk about my history with computers as well as my predictions for the industry.
#IAM #CloudSecurity #IamPulse
Please click the picture or here to see the article and video. kyler
This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
I have written lots of blogs (43 and counting!) under the heading “Let’s Do DevOps,” or simple, picture and code-heavy descriptions of how to succeed at many different modern DevOps tasks and architectures.
In this video I give a talk to an internal company audience about how we have replaced our internal-facing CI/CD static ec2 builders with container-driven pools that are replaced after every job.
These containers are rebuild from source nightly, and stored in one container registry location in one account, and a single secret in the Secrets Manager service in a single account stores the registration secret used by builders to register and start receiving jobs when they come up.
There are tons of security and operational benefits with this model, and I hope you enjoy this discussion and overview of them.
I was able to participate in a podcast discussion for NetworkCollective with Nick Russo and Craig Stansbury to discuss the new Cisco DevNet certifications and what it means for Cisco and the broader IT industry. Please listen in!
Here's my #HashiTalks2020 presentation about my company's transition from single-cloud, single-devops to cloud agnostic Terraform and multicloud Azure DevOps, pipeline and infra-as-code environments.
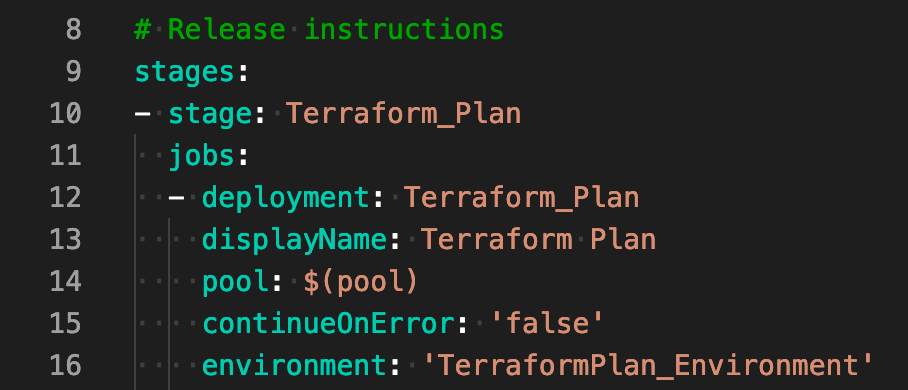
tl;dr: Here’s YML code that will build an Azure DevOps pipeline that can be run automatically as part of pull request validation (pre-merge) and requires manual approval by definably admin groups in order to proceed to touch resources.
Microsoft’s Azure DevOps (ADO) is an incredibly powerful CI/CD platform that is being rapidly developed by $MSFT. However, as with any rapidly-evolving product, the documentation sometimes leaves something to be desired. I solved a few problems with the help of the Azure DevOps development team and I thought I’d share my solutions. Hope they help.
Pairing Terraform with a CI/CD like Azure DevOps, Terraform Cloud, or GitHub Actions can be incredibly empowering. Your team can work on code simultaneously, check it into a central repo, and once code is approved it can be pushed out by your CI/CD and turned into resources in the cloud.